索引时帮助MYSQL高效获取数据的排好序的数据结构
索引数据结构
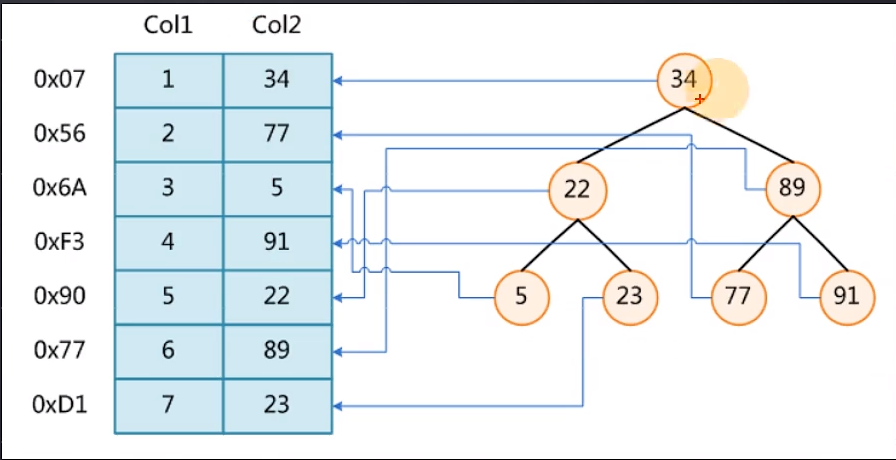
二叉树
左边的数,小于右边的数
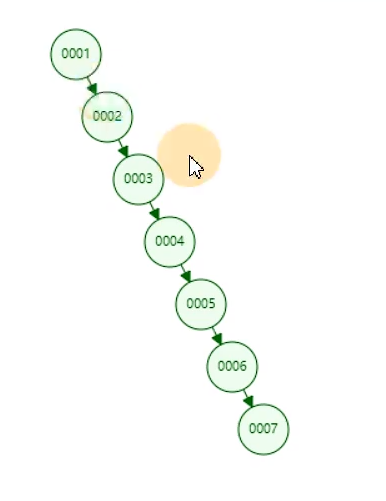
缺点:主键是递增的,如果使用二叉树,就成了链表
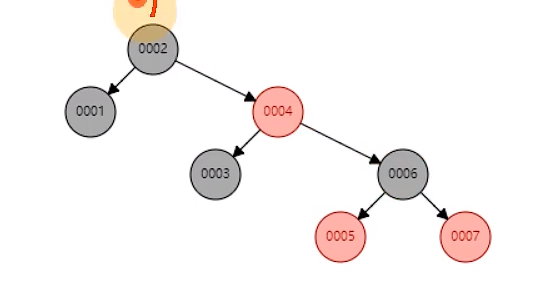
红黑树
面试经常问,hashmap底层就使用红黑树。
红黑树本质还是二叉树,全程二叉平衡树。当右边元素比左边高几层的时候,它会自我平衡树
缺点:数据量大的时候,树太高。假设500万数据 高度会到20,查找需要20次IO操作
改造:控制高度小于等于4,一个节点放很多索引 就是B-Tree
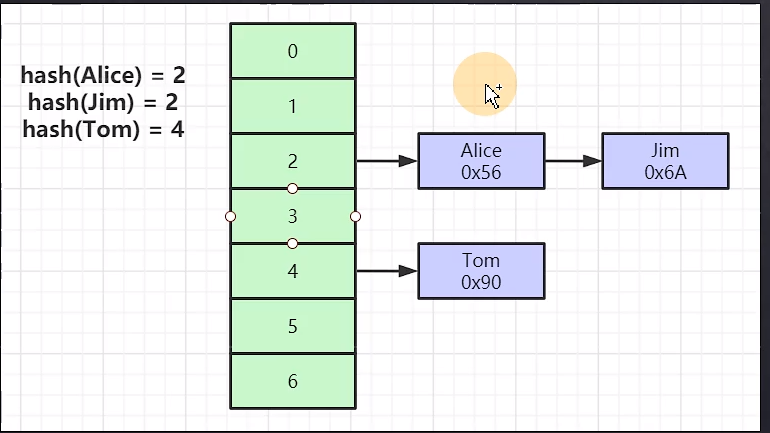
Hash表
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候hash索引要不B+树索引效率更高效
- 缺点:仅能满足 = in 不支持范围查询 比如name>’TOM’
- hash冲突问题
B-TREE
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排序
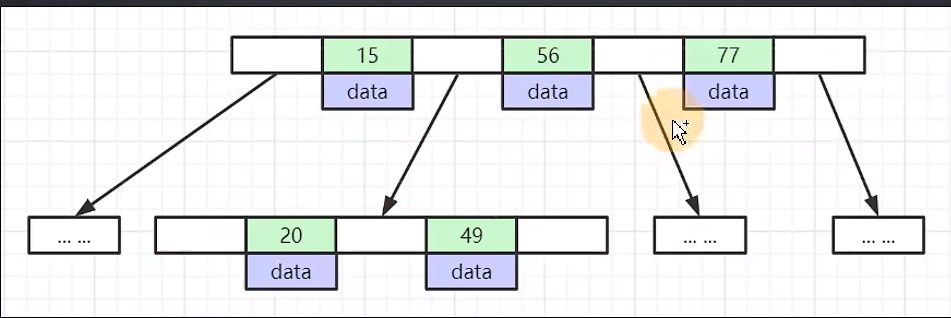
B+Tree(B-Tree变种)
-
非叶子节点不存储data,只存储索引(冗余)可以放更多的索引
-
叶子节点包含所有索引字段
-
叶子节点用指针连接,提高区间访问性能
-
mysql最终选择了B+Tree
-
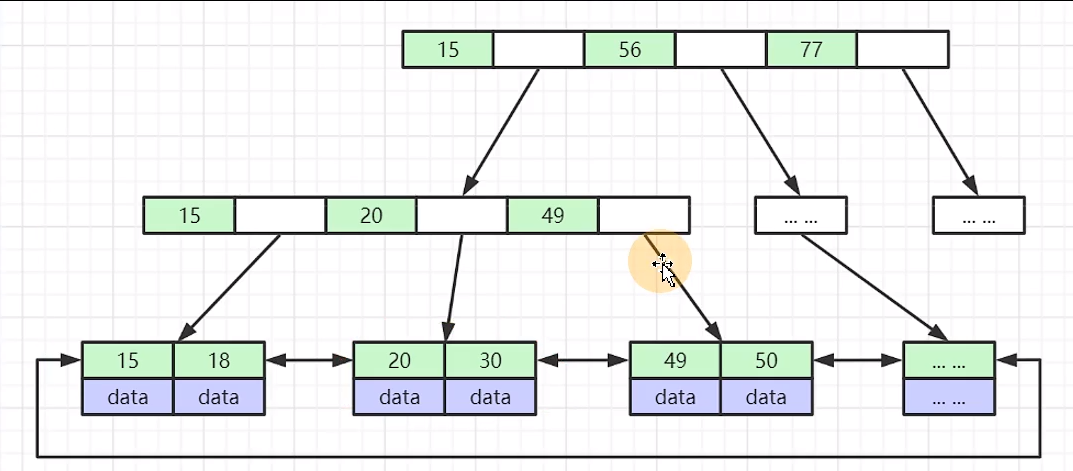
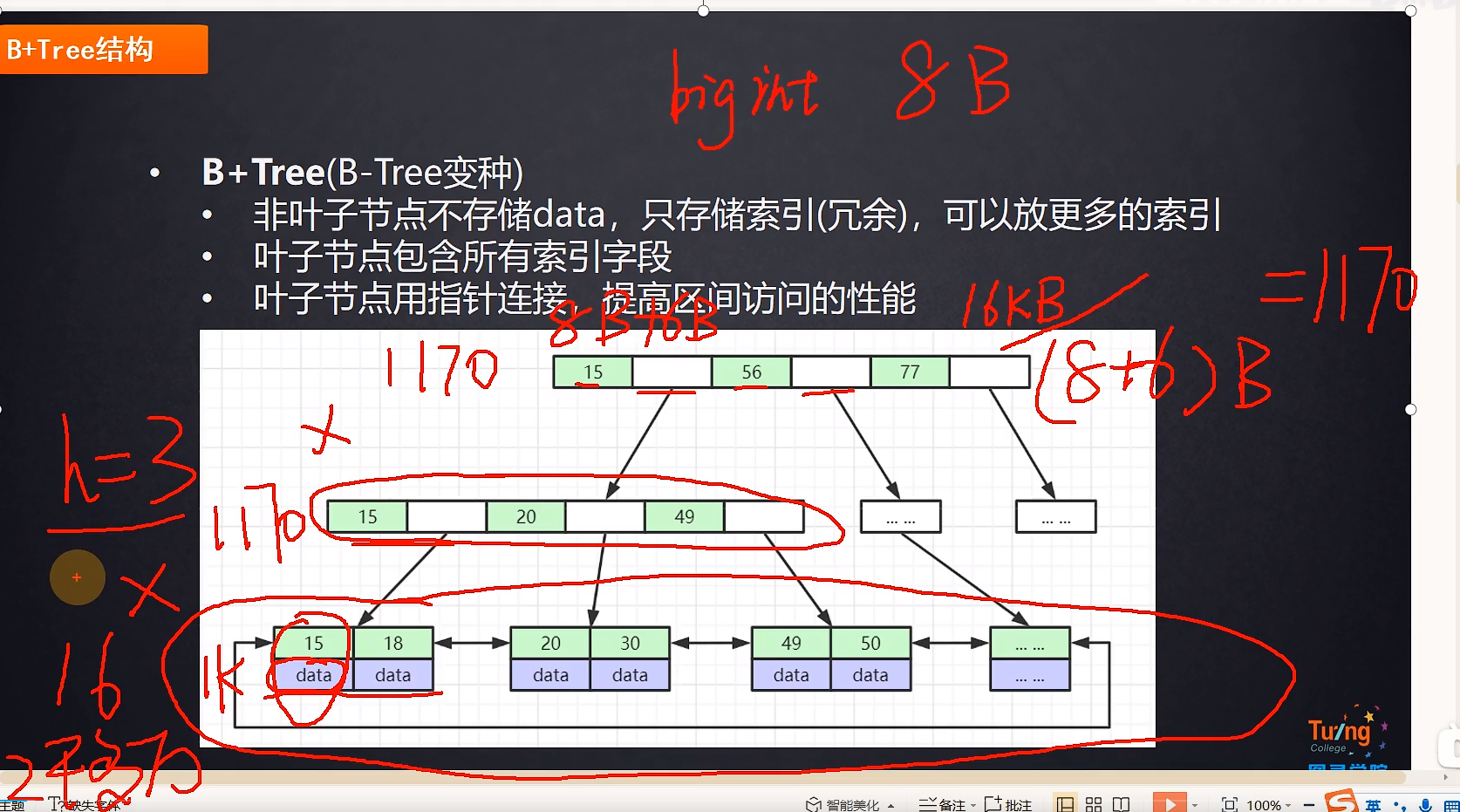
树的高度是三,叶节点预留16KB的空间,一个索引(bigint 为8B+下个节点磁盘地址6B) 一个节点能放多少个索引呢 16*1024/14=1170个索引
-
第二层 能对应1170个节点,第三层含有data 假设数据为1K 一个节点是16个数据。总数据量是多少呢
1170* 1170 * 16 =2千多万数据
查找效率呢,上千索引加载到内存中,折半查找,找到索引。再加载第二层的索引,折半查找,找到索引
数据结构
可视化网站 https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
存储引擎
MyISAM存储引擎索引实现
MyISAM 索引文件和数据文件时分离的
user表数据,存在到三个文件里,user_myisam.frm 表结构信息,user_myisam.MYD data数据
user_mysam.MYI index 索引数据
查询逻辑:在索引文件中,查找到索引 data 磁盘地址。根据磁盘地址把数据加载出来
innoDB存储引擎索引实现
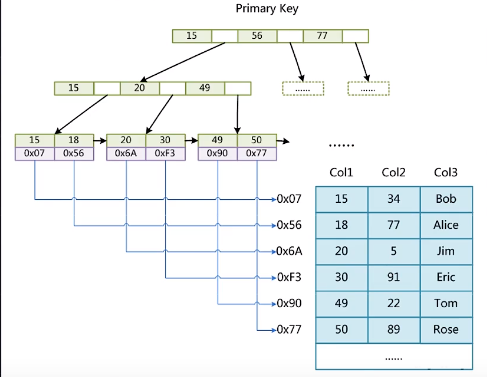
user表数据,存在两个文件里 user.frm 表结构信息 user.idb 索引和数据信息
- 表数据文件本身就是按照B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
- 为什么建议innodb表必须建主键,并且推荐使用整型的自增主键?
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
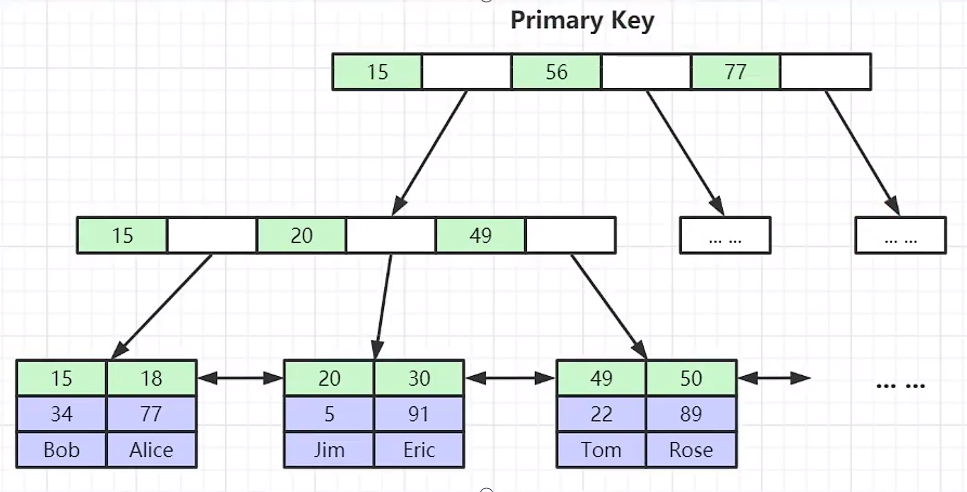
非主键索引,先根据索引找到主键,再根据主键去主键索引找寻找
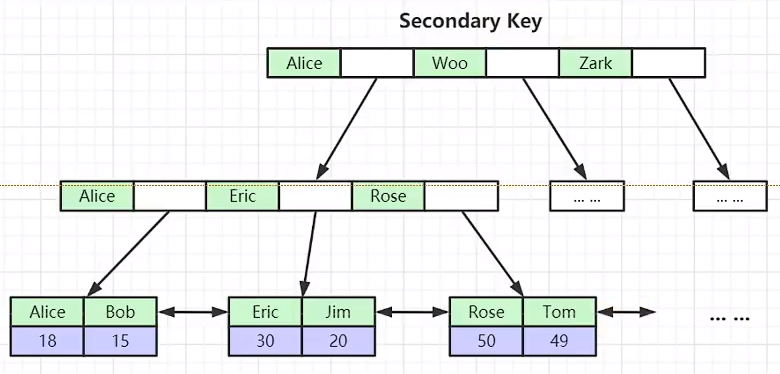
面试题常问:
聚集索引(聚簇索引) 和非聚集索引的区别
聚集索引:叶子节点包含了完整的数据记录
非聚集索引:索引和数据在不同文件内,索引处有数据的磁盘地址
B+树 和B-树的区别
B树的叶子节点之间没有双向指针,不能很好得支持范围查找
B+树得非叶子节点 不存储data元素,B树的非叶子节点存储了data元素
B+树 有很多冗余索引
为什么建议innodb表必须建主键,并且推荐使用整型的自增主键?
innodb表数据文件本身就是按照B+tree组织的,如果没有主键,mysql会找字段值唯一的一列作为索引
如果没有一列数据是唯一的,mysql会维护一个隐藏列rowid,作为索引。数据库的资源是宝贵的,要让数据库少做事情,所以要自己建主键,让mysql少做事,提供mysql性能
查找的过程有很多大小比对,整型比大小比字符串uuid效率高
自增:自增的话,数据永远是加在后面,不自增的话,mysql为了维护从左到右依次递增的有序性,会造成树的分裂,消耗性能
联合索引
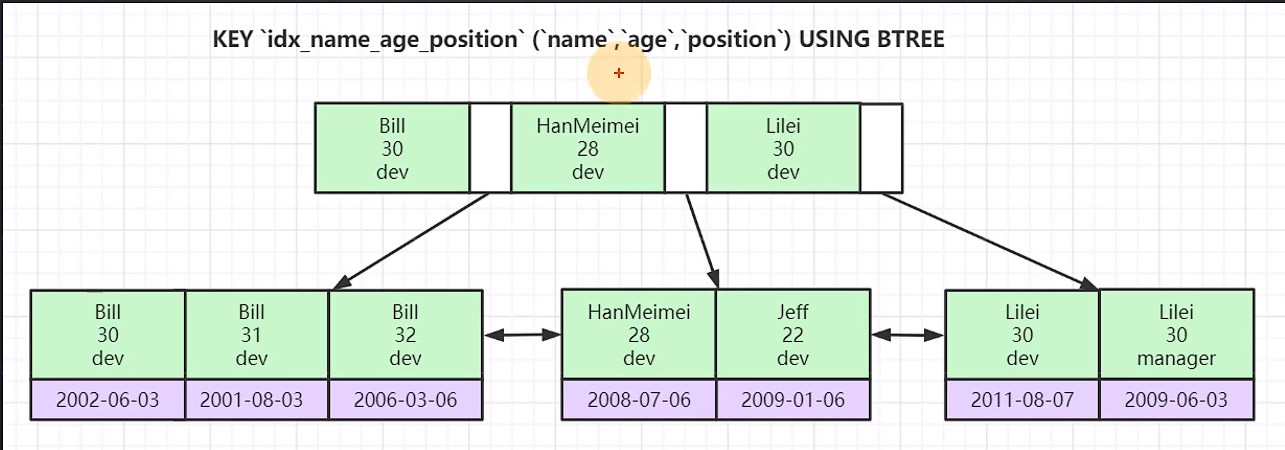
联合索引的底层存储结构长什么样
key 'idx_name_age_position' ('name','age','position') using btree
索引最左前缀原理
name age position 先按照name排序,当name相同的时候,再按照age排序,当name 和age都相同时,才按照position排序
如果直接查找age,所有的age并不是从左到右递增排序的,所以必须有最左前缀
索引规约
- 业务上具有唯一特性的字段,即使时组合字段,也必须建成唯一索引
- 超过三个表禁止join,需要join的字段,数据类型保存绝对一直,多表关联查询时,保证被关联的字段需要有索引